
At Cityflo, we use Amazon Web Services (AWS) for all of our tech infrastructure requirements. We majorly use services such as EC2, RDS, ElastiCache, Lambda, S3, Cloudwatch, and ECS.
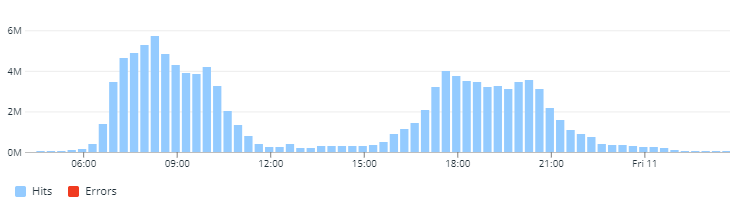
Before diving deep into the infrastructure, let's talk a little bit about the traffic pattern at Cityflo. Our services start around 6:30 AM in the morning and end around 10 PM in the evening with a downtime of a few hours in the afternoon. The buses in the morning are less spread out across time compared to the evening. This means that the system needs to be resilient towards any failure. The common outcomes of these failures are generally slow APIs or nothing working at all. Well, no one wants to wake up to a panic call when things go south! 🙂
A few months back we were running all of our application servers on EC2 managed by AWS Opsworks. Opsworks is a managed service from AWS which helps you manage/automate a few tasks that can run using Chef.
One of the major problems with Opsworks was that it used to take more than 10 minutes to bring up an EC2 instance to be used in the fleet. With this amount of start time, the demand will always beat the supply for computing resources when the traffic is ramping up. This prevented us from using the load-based scaling configuration available in the Opsworks. Another scaling option that Opsworks provides is time-based scaling. We used time-based scaling for quite some time until we started running into several issues. The most common issue was that it had no simple way of retrying a boot up once an instance failed in the first attempt. This caused the rest of the servers to overload and sometimes result in a cascading failure.
It was clear that the existing architecture was failing to provide what we promise to our customers!
The Requirements
- Cost-Effective: The infrastructure should be auto-scaling as per the needs.
- Fast: The scale-out events should happen within seconds.
- Self-healing: We don't have a dedicated DevOps team (yet). Any loss of an instance should get replaced without requiring manual intervention.
- Simple: Our team is very small and keeping things simple goes a long way for us.
The Options
With our requirements clear to us, it seemed like running apps in containers is the way ahead. With containers in mind, there are several options that we thought of -
- Kubernetes
- Docker Compose
- AWS Elastic Container Service + AWS Fargate
All of these three options are cost-effective, fast, and implement self-healing in some way or the other. When comparing them for simplicity we came to the following conclusion -
- Kubernetes ❌
- Docker Compose ❌
- AWS Elastic Container Service + AWS Fargate ✅
Following are the descriptions of ECS and Fargate from AWS docs:
Amazon Elastic Container Service (ECS) is a fully managed container orchestration service that makes it easy for you to deploy, manage and scale containerized applications.
AWS Fargate is a serverless compute engine that lets you focus on building applications without managing servers. Fargate removes the need to own, run, and manage the lifecycle of a compute infrastructure.
This was perfect for us! We changed our CI/CD pipeline to build all of our applications as Alpine based container images (Less than 100 MB!) which are then pushed to ECR (another service from AWS to store container images) and then deployed on ECS. This eliminated a whole set of issues that could happen because of a network failure e.g. Github being down or PyPi not responding in time.

We went ahead with Alpine Linux because it's small, simple, and secure. It comes with no unnecessary packages which makes it an excellent candidate for container-based applications. Having a small image size is also important to quickly scale up your cluster.
Fargate offers another lucrative feature from a cost standpoint. Fargate Spot! Fargate Spot is a capability on AWS Fargate that can run interruption tolerant ECS tasks at up to a 70% discount off the Fargate price. AWS uses spare capacity in the cloud to run your tasks. When the capacity for Fargate Spot is available, you will be able to launch tasks based on your specified request. When AWS needs the capacity back, tasks running on Fargate Spot will be interrupted with two minutes of notification.
This behavior of Fargate Spot fits a stateless REST API for high availability. You can use either CPU-based or memory-based scaling options available in ECS to scale out your cluster.
ECS also integrates very well with Cloudwatch. With Container Insights, you can monitor your containerized applications very closely.
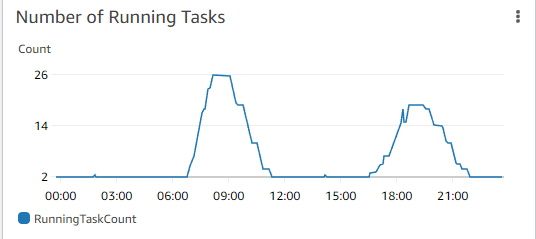
Conclusion
After migrating to this architecture, we haven't had any downtimes or slow APIs because of scaling issues. Apart from the saved developer hours for maintenance work, this has also resulted in around 40% less infrastructure cost compared to the previous architecture.
Until next time! Happy coding!